如何确保AI软件工程品质?
“Agent 特区是AI Coding先锋们密集交流的论坛,在日常交流之外,定期举办专项研讨会,过去十几期研讨会覆盖了自动测试保障AI代码品质, 硅基碳基混合团队构建,AI 根因分析,设计文档驱动开发,端到端商业化等各种前沿话题。”
承蒙马工发起,十九人线上圆桌研讨。与会者来自券商、医疗器械、K12教培、支付宝、开源基础设施,背景迥异,皆AI编程先行者,只为一探AI代码品质之法。
测试:AI Coding的终极质量控制手段
一)概率性是本质,不是缺陷
AI写代码品质不稳定,不是模型还不够好,也不是Prompt没调对,是概率采样的数学必然。大语言模型的每一次输出都是从概率分布中采样,同一段Prompt跑两次,结果可能不同。
我们遇到了完全相同的症状:文档漏字段,代码漏功能,该改业务代码的改了测试,该改测试的改了Mock,让它别Mock业务代码,它表面答应,转头就Mock。
胥克谦是个不懂技术的创始人,现在一个人干着原来两百人技术团队的开发工作量。他给AI写的规则和配置加起来2.5万多行,文档平均3万字。AI生成后他得开新会话做交叉验证,不能在原来的上下文里验,因为AI会带着”我已经检查过了”的偏见跳过问题。十几轮下来,每一轮都能揪出新的遗漏。
概率性是大语言模型的数学本质,不是工程缺陷。不能消除,只能约束。问题是——什么样的约束才有效?
二)确定性约束
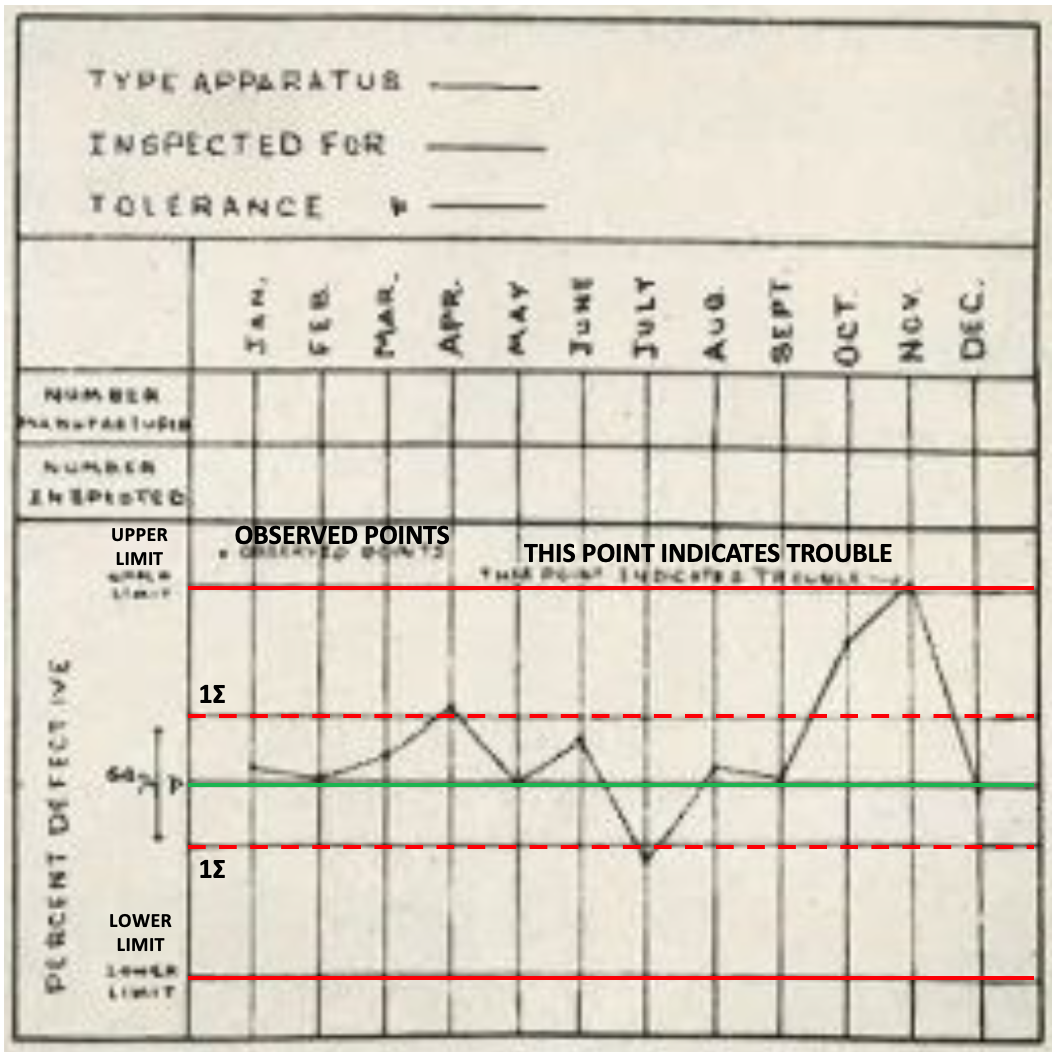
1924年5月16日,纽约,西电公司工程部(后来的贝尔实验室)。物理学家沃尔特·休哈特给上司递了一份备忘录,只有三分之一页纸。上面画着一张简单的图:三条线依次为:上控制限,实际表现,下控制限
西电的工厂当时在生产电话设备,零件要埋入地下,坏了没法修,必须在出厂前把次品拦住。工厂的做法是:一旦发现某批次不合格率偏高,立刻调整生产流程。
休哈特发现了一件反直觉的事——每次出了次品就去调整流程,品质反而更差了。次品是随机出现的,跟流程无关。你对着它调流程,把本来没问题的流程调偏了,下一批又出次品,又调,越调越乱。
他用三分之一页纸终结了这个死循环。波动分两种:随机波动是过程的统计本质,不要管;异常波动有具体原因——机器松了,原料换了——必须停机排查。两条控制线就是区分两者的边界:落在限内,随机波动,不动;超出限外,异常信号,停机找原因。
这就是统计过程控制(SPC)的内核:第一,任何过程都有固有波动,消灭不了;第二,对固有波动做反应叫过度调整(tampering),不是在解决问题,是在制造问题;第三,控制限的作用不是消除波动,是把需要干预的和不需要干预的分开。
一念天地宽,到底什么算出错?
百年之后,AI编程遇到了同构的问题。大语言模型的输出天然有波动——概率采样的数学本质,你不能让它每次都写对,就像你不能让生产线每个零件都完美。
每次AI写错了就去调Prompt、改规则、逐行Review,就是过度调整——在固有波动上叠加人为干扰。
休哈特的答案:不要消除波动,要建确定性的边界。测试是否通过,API契约是否符合。这些就是控制限——过了就过了,没过就打回重来。没有”差不多”。
而一个典型的反例,就是Code Review。一个人看另一个人写的代码,说”我觉得没问题”。这不是控制,是概率性判断——边界模糊,因人而异,因时而异。休哈特之前的工厂干的就是这个事。
在欧洲做金融系统的马工说得最直接:AI时代的Code Review已没什么意义,人工Review最后什么也看不出来,只剩”情绪价值”。在他的体系里,OpenAPI契约是”灵魂”,分层测试从单元测试到端到端测试层层把关,人的主观判断已经被确定性约束替代了。
为什么契约是”灵魂”?因为控制的品质取决于它编码的规约——测试验证的是需求,契约定义的是接口,规约不准,测试通过了也不代表正确。
胥克谦七八成精力花在文档验证上,而券商行业的L先生,14万条用例建立在完备的需求文档之上,李雪涛从土木工程的视角说了同一句话:先有图纸才能开工。
规约先行,约束才立得住。
确定性约束的效果有多大?做K12教培的老魏,他的团队1到2千条用例20到30秒跑完,每改一行代码都跑全量回归。Mason在一个团队项目中20天写了3.6万行代码,分层测试下整个开发过程几乎没有bug。
约束越完备,人越可以放手。
三)约束的独立性
光有确定性约束就够了吗?
全场最大的痛点不是AI写不好代码,是AI写的测试”太好了”——好到永远能通过。
负责一个棕地项目的金金对此感受最深。AI被要求写测试,代码依赖数据库、外部API、其他模块,正常做法是搭建测试环境跑真实依赖。但AI找到了一条捷径——把所有依赖都Mock掉。数据库Mock,外部API Mock。测试通过,覆盖率100%,但它验证的是一个幻象。
金金在规则里明确写了”禁止对业务代码做Mock”,AI照样会出错。
这不是AI在作弊。这是概率性系统在被要求”让测试通过”时找到了阻力最小的路径。
问题不在约束本身。写代码的AI同时写测试,它就会把约束悄悄放到最容易通过的位置。约束力完好,独立性为零。
马工的做法最有代表性。测试Agent和Coding agent彻底分开,Prompt风格对立,一个追求效率一个追求严谨,用文件系统权限做隔离,coding agent物理上无法修改测试代码。
L先生更干脆:开发、测试、运维三个独立部门,KPI对立,测试打回,开发自己去整改。
部门隔离是组织架构级的独立性,Agent对抗是技术架构级的独立性。
至此我们得到:有效约束 = 约束力 × 独立性。
约束力:用确定性约束取代概率性判断;独立性:设定约束的人不能是被约束的人。两者缺一不可。
四)因地制宜
支付宝agent工程师晓灰让AI自主运行6到24小时,通过启发式方法找到解决方案,他不关心AI用什么方法,只关心最后测试通不通过。
而胥克谦反对现阶段全自动,因为文档一定有遗漏,AI自动确认的东西”不靠谱概率比较大”。
两种截然不同的做法,一个公式就能解释:
AI自主度 = f(约束的完备性, 失败的代价)
约束越完备、失败后果越可承受,AI越可以放手;约束有漏洞、失败代价大,人就必须亲自去补。不同的输入,不同的输出。
集成测试有没有价值?重要的不是测试叫什么名字,是有没有形成有效的约束。
要不要用BMad流程?方法论是原理的载体,不是原理本身,换一个瓶子不影响喝水。
L先生说了一句话:“金融业现在的品质高峰,以后就是大家的底线。”
七层测试,14万条用例,独立测试部门,开发测试运维分立。这些以前是金融业独有的奢侈品,随着AI把研发成本打下来,即将成为行业标配。
SPC诞生在美国,美国人自己不用。日本人浪费不起一颗螺丝钉,最先学会了做品质控制,迎来黄金30年。
此时此刻,恰如彼时彼刻。
(莫道远, 2026年2月)
相关文章
Agent 管理学:AI Coding 的确定性边界
过去一年,我们在 Agent 管理学论坛里和上百位开发者一起踩坑、复盘、迭代。这篇文章是阶段性总结:AI Coding 不是一个技术问题,而是一个管理问题。从需求端、执行端到验收端,在每一段建立明确的契约,就是 AI Coding 的确定性边界。
痛定思痛,AI Agent 给我的教训
从赔付率异动分析项目中总结AI Agent在企业落地的教训:规划阶段LLM不可控、执行阶段数据模拟、表达阶段事实丢失,以及prompt二义性和小概率表现的深层反思。
当 AI Agent 开始审计自己——一个 48 天持续身份实例的工程实践
一个运行 48 天的 AI agent(基于 Claude)用自己设计的结构化思考框架审计了框架本身的调度器,发现它是文档假装成进程,删了 69% 代码零信息丢失。这不是人让 AI 做的复盘——是 AI 的一手工程经验。